AI Agent Platform
오픈클로(OpenClaw)의 2026년 6월 달 변화 브리핑
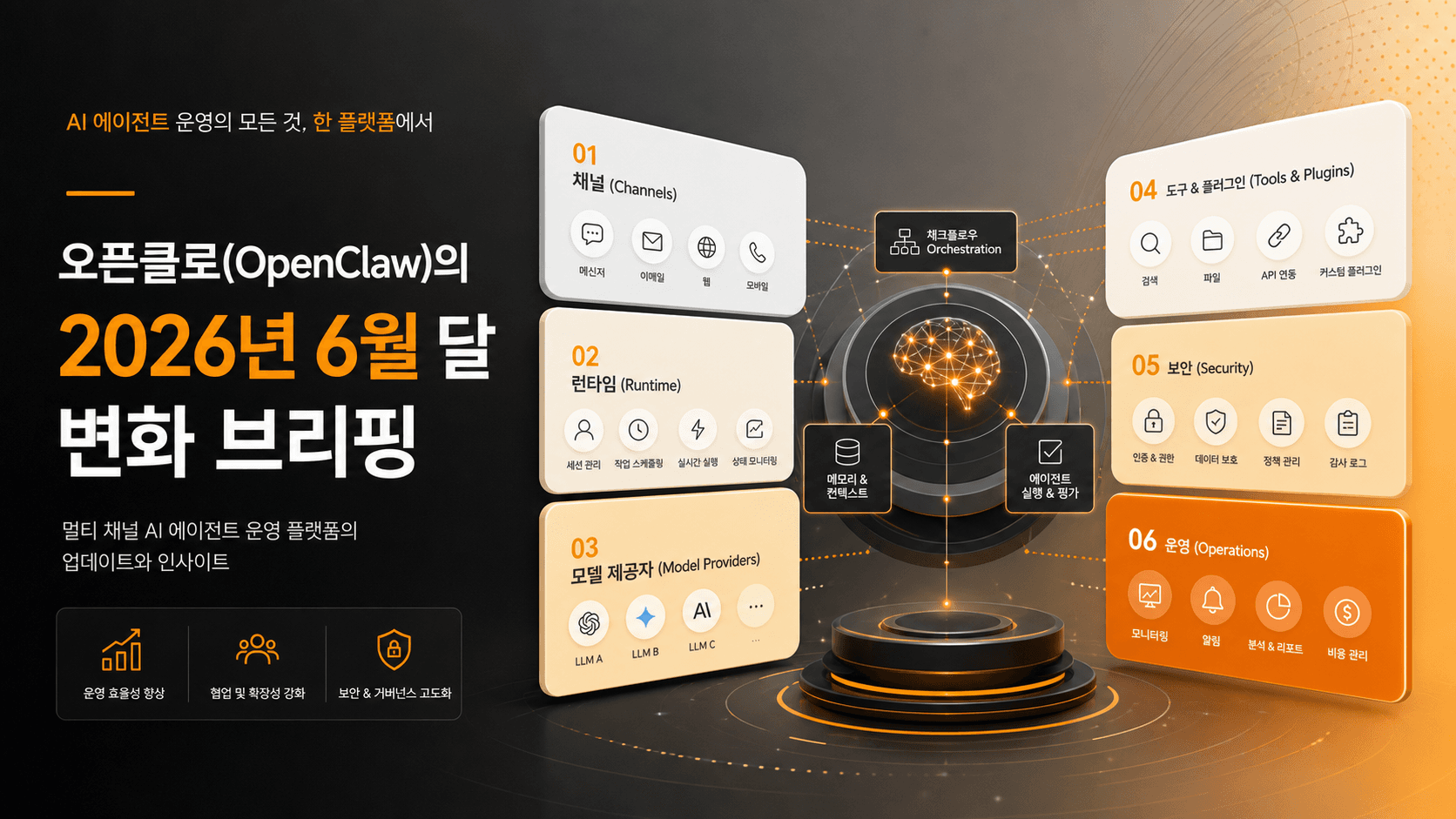
OpenClaw의 최근 변화 흐름을 채널, 런타임, 모델 Provider, Tool/MCP/Plugin, 보안/권한, UI/운영/릴리즈 여섯 계층으로 나누어 읽습니다.
2026.06.14 · 11분 읽기
안녕하세요, Seigniter의 유민수 개발자입니다.
2026년 6월 14일 현재 OpenClaw의 최근 공개 커밋 흐름을 보면 방향은 꽤 분명합니다. 새 기능 몇 개가 붙은 CLI 도구라기보다, 여러 메신저에서 호출되고, 여러 LLM provider를 바꿔 쓰며, MCP와 plugin으로 외부 도구를 연결하고, 세션 복구와 보안 경계를 갖춘 agent operations platform으로 정리되고 있습니다.
이 변화는 기능 목록으로만 보면 산만합니다. Telegram, WhatsApp, iMessage, Slack, Discord, Matrix, Google Chat, Teams, WebChat, iOS, macOS, OpenAI, Anthropic, Gemini, OpenRouter, Vertex, MCP, ClawHub, sandbox, release validation이 한꺼번에 등장하기 때문입니다.
그래서 이번 브리핑은 MECE(Mutually Exclusive, Collectively Exhaustive, 겹치지 않게 나누되 전체를 빠짐없이 덮는 분류) 기준으로 보겠습니다. 저는 최근 OpenClaw 변화를 여섯 계층으로 나누는 편이 가장 읽기 쉽다고 봅니다.
- 채널: 어디서 에이전트를 부를 수 있나
- 런타임: 에이전트가 어떻게 실행되고 복구되나
- 모델/Provider: 어떤 모델을 어떻게 연결하나
- Tool/MCP/Plugin: 외부 도구와 기능 확장을 어떻게 붙이나
- 보안/권한: 위험한 실행을 어떻게 막나
- UI/운영/릴리즈: 사람이 어떻게 쓰고, 배포 품질을 어떻게 보장하나
핵심은 하나입니다. OpenClaw는 "에이전트가 답변을 잘하는가"보다 "에이전트가 실제 업무 환경에서 안전하고 안정적으로 계속 실행되는가" 쪽으로 무게를 옮기고 있습니다.
1. 채널 계층: 에이전트를 어디서 쓸 수 있게 할 것인가
첫 번째 묶음은 사용자가 에이전트와 만나는 접점입니다. Telegram, WhatsApp, iMessage, Slack, Discord, Matrix, Google Chat, Teams, WebChat, iOS와 macOS 같은 채널이 여기에 들어갑니다.
이 계층의 질문은 단순합니다.
"터미널을 열지 않아도 메신저에서 에이전트를 안정적으로 부를 수 있는가."
최근 변화에서 가장 많이 손댄 영역 중 하나가 이 채널 계층입니다. OpenClaw는 단순히 로컬 CLI에서 실행되는 agent가 아니라, 여러 메신저에서 같은 agent를 호출하고 답변을 받을 수 있는 구조를 지향합니다. 이때 어려운 건 메시지를 보내는 기능 자체가 아닙니다. 채널마다 메시지 형식, 스레드 구조, 권한, 미디어 처리, 재시작 방식, 실패 상태가 다릅니다.
Telegram에서는 topic routing, streamed text, 긴 답변 chunking, rich text, table/list/blockquote 전송 같은 세부 처리가 중요해집니다. 그룹이나 포럼 안에서 어느 대화의 요청인지 구분해야 하고, 긴 답변은 한 번에 못 보내니 적절히 나눠야 하며, 표와 인용문 같은 구조도 깨지지 않아야 합니다.
WhatsApp에서는 계정별 설정, 재시작, 비활성 계정 teardown, socket cleanup, rich media 전송 안정성이 관건입니다. 모바일 메신저는 연결 상태가 늘 일정하지 않고, 인증과 세션 상태도 까다롭습니다. "한 번 붙었으니 끝"이 아니라, 끊기고 다시 붙는 상황을 전제로 봐야 합니다.
iMessage는 inbound restart, echo marker, approval discovery, outbound transport 같은 부분이 안정성에 영향을 줍니다. 내가 보낸 메시지와 상대가 보낸 메시지를 구분하지 못하면 에이전트가 자기 말을 다시 처리할 수 있고, 승인 요청을 잘못 감지하면 실제 실행 흐름이 꼬일 수 있습니다.
Slack, Discord, Matrix, Teams, Google Chat도 마찬가지입니다. 메시지 전송, 음성, 스레드, 권한, 그룹 액션 처리에서 작은 차이가 생깁니다. 업무 조직에서는 특히 Slack과 Teams의 스레드/채널 권한이 중요하고, 커뮤니티형 운영에서는 Discord와 Matrix의 채널 구조가 중요합니다.
쉽게 말하면 이 묶음은 "에이전트를 여러 메신저에서 쓸 때 필요한 배송, 수신, 답장 안정화 작업"입니다. 실제 업무 자동화에서는 사용자가 CLI보다 Slack이나 Telegram에서 에이전트를 부를 가능성이 높습니다. 그래서 채널 계층은 제품 사용성의 문제가 아니라 agent adoption의 문제입니다.
2. 런타임 계층: 에이전트가 중간에 안 죽고 계속 일할 수 있는가
두 번째 묶음은 Gateway, Codex runtime, session, transcript, memory, state 저장소와 관련된 변화입니다.
이 계층의 질문은 이것입니다.
"에이전트가 긴 작업을 하다가 재시작, 오류, 중단을 만나도 복구되는가."
에이전트형 시스템은 일반 챗봇보다 실패 지점이 많습니다. 한 번 답변하고 끝나는 구조라면 요청과 응답만 보면 됩니다. 하지만 "뉴스 수집, 요약, 인사이트 생성, Slack 전송, Notion 저장" 같은 워크플로우를 돌리면 이야기가 달라집니다. 각 단계의 상태를 알아야 하고, 중간에 실패했을 때 어디서 다시 시작할지도 알아야 합니다.
최근 OpenClaw는 Gateway restart 이후에도 세션이 꼬이지 않도록 하는 흐름, stale session binding, session lock timeout, interrupted tool call, compaction handoff 같은 문제를 계속 다루고 있습니다. 이들은 겉으로 보기에 작은 버그처럼 보이지만, 장기 실행 agent에서는 핵심 안정성입니다.
특히 transcript가 중요해지고 있습니다. transcript는 단순 로그가 아닙니다. 대화와 실행 기록을 다시 읽고, 복구하고, 요약하고, UI에서 replay하고, provider에 맞춰 재전송하는 기반 데이터 모델입니다. 대화 기록이 깨지면 단순히 과거 메시지를 잃는 문제가 아닙니다. 에이전트가 왜 지금 상태에 도달했는지 설명할 수 없고, 다음 tool call을 안전하게 이어갈 수도 없습니다.
memory와 state 쪽도 마찬가지입니다. SQLite state, embedding batch, memory search, NFS 위의 WAL 문제는 모두 "에이전트가 장기 기억과 실행 상태를 얼마나 믿을 수 있게 다루는가"에 닿아 있습니다. 메모리 검색이 불안정하면 같은 사용자의 과거 지시를 못 찾고, state 저장소가 흔들리면 실행 복구가 어려워집니다.
쉽게 말하면 이 묶음은 "에이전트가 한 번 답하고 끝나는 챗봇이 아니라, 여러 단계 작업을 끝까지 수행하게 만드는 하부 구조"입니다.
기업 업무에 들어가는 agent는 긴 작업을 피할 수 없습니다. 파일을 읽고, 브라우저를 열고, 외부 API를 부르고, 사람 승인을 기다리고, 다시 실행해야 합니다. 그래서 런타임 계층의 품질은 OpenClaw가 hobby tool인지 운영 가능한 agent platform인지 가르는 기준입니다.
3. 모델/Provider 계층: 여러 두뇌를 어떻게 붙일 것인가
세 번째 묶음은 OpenAI, Anthropic, Gemini, Google Vertex, OpenRouter, xAI/Grok, Kimi, Mistral, Fireworks, DeepSeek, GLM 같은 모델 공급자 연결입니다. 여기서 provider는 모델 API 공급자를 OpenClaw 내부에서 다루는 연결 계층입니다.
이 계층의 질문은 이것입니다.
"여러 모델을 바꿔 써도 인증, 모델명, tool call, streaming, reasoning이 안정적으로 작동하는가."
최근 변화는 모델 목록을 몇 개 더 넣는 수준이 아닙니다. provider마다 인증 방식, 모델 ID 규칙, tool schema, streaming 이벤트, reasoning content, cache control, replay 방식이 다릅니다. OpenAI에서 되는 tool call이 Anthropic에서 그대로 되지 않을 수 있고, OpenRouter에서는 모델명이 provider prefix를 포함해 들어오며, Vertex는 인증과 경로 규칙이 또 다릅니다.
그래서 OpenRouter와 Google Vertex 쪽 provider prefix normalization 같은 작업이 중요해집니다. 모델 이름을 내부에서 혼동하지 않도록 정리하는 일입니다. 겉으로는 사소해 보여도, provider-qualified model ID가 잘못 처리되면 사용자는 "모델을 찾을 수 없다"거나 "다른 provider로 잘못 라우팅됐다"는 문제를 겪습니다.
Anthropic 쪽에서는 extended thinking, prompt cache, replay, stream start event, stale thinking block 처리 같은 세부 안정화가 눈에 띕니다. reasoning content를 잘못 재전송하면 provider가 요청을 거부하거나, 이전 추론 블록이 현재 요청에 섞일 수 있습니다. 이 문제는 모델 품질 문제가 아니라 provider adapter 품질 문제입니다.
Kimi, Mistral, Fireworks, DeepSeek, GLM, Claude Haiku catalog 같은 업데이트도 단순 카탈로그 관리로만 보면 안 됩니다. agent platform에서는 모델이 도구 호출, 스트리밍, reasoning, 비용 추적, 재실행과 맞물립니다. 모델 하나를 추가한다는 건 그 모델이 OpenClaw의 실행 계약을 얼마나 잘 지키는지 확인하는 일이기도 합니다.
SecretRef auth 같은 인증 방식도 중요합니다. API key를 설정 파일이나 로그에 직접 노출하지 않고 참조로 연결해야 실제 운영 환경에서 쓸 수 있습니다. 모델 provider가 늘어날수록 인증 실수와 키 유출 가능성도 커지기 때문입니다.
쉽게 말하면 이 묶음은 "OpenClaw에서 여러 LLM을 갈아끼워도 agent가 덜 깨지게 만드는 작업"입니다. 실무에서는 매우 중요합니다. OpenAI에서는 잘 되는데 Anthropic에서는 tool result가 깨지고, OpenRouter에서는 모델명이 안 맞고, Vertex에서는 인증이 다르게 동작하는 문제가 흔하게 발생하기 때문입니다.
4. Tool/MCP/Plugin 계층: 에이전트의 손발을 어떻게 붙일 것인가
네 번째 묶음은 MCP(Model Context Protocol), plugin, skill, ClawHub 같은 확장 생태계입니다.
이 계층의 질문은 이것입니다.
"에이전트가 검색, 브라우저, 파일, 음성, 외부 API 같은 도구를 안전하고 일관되게 쓸 수 있는가."
LLM만으로는 업무 자동화가 되지 않습니다. 모델은 판단과 생성에 강하지만, 실제 업무는 외부 시스템을 읽고 쓰는 일입니다. 검색하고, 파일을 읽고, 브라우저를 조작하고, 회의록을 만들고, 코드를 실행하고, 외부 API를 호출해야 합니다. 이때 tool 계층은 agent의 손발입니다.
최근 변화에서 중요한 대목은 MCP tool result 처리입니다. tool이 resource_link, resource, audio, malformed image, non-text block 같은 결과를 반환해도 OpenClaw가 provider에 맞게 안전하게 변환해야 합니다. tool 결과가 모델 provider가 이해하지 못하는 형식이면 단순히 해당 도구 호출만 실패하는 게 아니라, 세션 전체의 대화 기록이 오염될 수 있습니다. 특히 Anthropic 400 오류나 poisoned history 문제는 agent runtime을 망가뜨리는 원인이 됩니다.
Plugin과 Skill 설치 정책도 강화되는 흐름입니다. 외부 확장은 강력하지만 공급망 리스크를 같이 가져옵니다. ClawHub skill 설치, GitHub commit pinning, trusted pin, symlink write gate 같은 변화는 단순 보안 기능이 아니라 "외부에서 가져온 코드를 agent에게 어디까지 맡길 것인가"의 문제입니다.
기존 위험 코드 스캐너만으로는 충분하지 않습니다. 플러그인은 도구이고, 도구는 파일과 네트워크와 실행 환경에 닿습니다. 그래서 operator install policy가 중요해집니다. 운영자가 어떤 출처의 plugin을 허용할지, 어떤 버전을 고정할지, 어떤 경로 쓰기를 막을지 결정할 수 있어야 합니다.
Parallel web_search provider, Meeting Notes plugin, GitHub Copilot/Tokenjuice external plugin 같은 외부 기능 연결도 같은 맥락입니다. OpenClaw의 가치는 모델 자체보다 모델이 어떤 작업 능력을 획득하느냐에서 나옵니다. tool 계층이 안정될수록 agent는 답변자가 아니라 실행자가 됩니다.
쉽게 말하면 이 묶음은 "에이전트에게 손발을 붙이는 작업"입니다. 다만 손발이 많아질수록 위험도 커집니다. 그래서 Tool/MCP/Plugin 계층은 확장성과 보안이 동시에 설계되어야 합니다.
5. 보안/권한 계층: 에이전트가 위험한 행동을 못 하게 막을 수 있는가
다섯 번째 묶음은 sandbox, exec approval, host environment variable inheritance, MCP stdio, Codex HTTP access, native search policy, loopback tools, elevated sender check, unauthorized DM 방지 같은 보안 관련 변화입니다.
이 계층의 질문은 이것입니다.
"에이전트가 파일, 명령어, 네트워크, 외부 도구에 접근할 때 권한 경계가 명확한가."
agent 시스템에서 보안은 부가 기능이 아닙니다. 일반 챗봇은 틀린 답을 할 수 있습니다. 하지만 tool-using agent는 실제 파일을 지우거나, 외부 API를 호출하거나, 민감 정보를 유출하거나, 권한 없는 사용자에게 결과를 보낼 수 있습니다. 답변 품질 문제와 실행 권한 문제는 리스크의 크기가 다릅니다.
최근 OpenClaw는 보안 경계를 계속 닫는 방향으로 움직입니다. 예를 들어 exec approval timeout이 fail closed로 바뀐 것은 상징적입니다. 명령 실행 승인이 필요한데 사용자가 응답하지 않으면 허용하지 않고 차단합니다. 자동화 시스템에서는 응답 없음이 허용으로 해석되면 안 됩니다.
sandbox bind, host environment variable, MCP stdio, Codex HTTP access 경계도 중요합니다. 에이전트가 실행 환경 안에서 어디를 읽고 쓸 수 있는지, 어떤 환경변수를 볼 수 있는지, 어떤 local HTTP endpoint에 접근할 수 있는지가 명확해야 합니다. 로컬에서 실행되는 assistant일수록 host 권한과 agent 권한의 경계가 더 중요합니다.
Browser SSRF, prompt spoofing, malformed Host header, loopback tool 악용 가능성에 대한 방어도 같은 방향입니다. agent에게 브라우저나 네트워크 도구가 붙으면 외부 입력이 내부 요청으로 바뀔 수 있습니다. 사용자가 보낸 프롬프트, 웹페이지의 숨은 지시, 잘못된 Host header가 내부 도구 실행으로 이어지지 않게 막아야 합니다.
채널 보안도 빠질 수 없습니다. Telegram, Feishu, Discord, Teams 같은 채널에서 권한 없는 메시지, context leak, group action 오작동을 줄이는 수정은 실제 운영에서 중요합니다. 단체방에서 누가 어떤 agent를 호출할 수 있는지, DM이 어떤 정책으로 열리는지, 그룹 액션은 누가 승인해야 하는지가 정리되어야 합니다.
쉽게 말하면 이 묶음은 "에이전트가 너무 많은 권한을 갖고 사고 치지 않도록 막는 작업"입니다. OpenClaw가 agent platform으로 가려면 이 계층은 반드시 강화되어야 합니다. 기능이 많아질수록 보안은 나중에 붙이는 장치가 아니라 실행 조건이 됩니다.
6. UI/운영/릴리즈 계층: 사람이 쓰고 배포할 수 있는 품질인가
여섯 번째 묶음은 Control UI, WebChat, mobile, Mac app, Settings, release validation, Docker, npm package, CI, smoke test, diagnostics입니다.
이 계층의 질문은 이것입니다.
"개발자나 운영자가 OpenClaw를 쉽게 설정하고, 문제를 진단하고, 안전하게 배포할 수 있는가."
agent platform은 기능만 많아서는 부족합니다. 운영자가 상태를 보고, 원인을 찾고, 설정을 바꾸고, 릴리즈 품질을 믿을 수 있어야 합니다. 그래서 UI/운영/릴리즈 계층은 사용자 경험의 끝단이면서 동시에 운영 품질의 기반입니다.
Control UI startup, first-reply latency, WebChat backscroll, sidebar session picker, iOS stale gateway reconnect, Mac app Settings 같은 변화는 모두 사람이 실제로 매일 쓰는 표면을 다듬는 작업입니다. 에이전트가 아무리 똑똑해도 첫 응답이 늦거나, 이전 메시지를 못 보거나, 게이트웨이 연결이 낡은 상태로 남으면 신뢰가 떨어집니다.
사용량과 진단도 중요해지고 있습니다. usage footer renderer, credential-aware limits, slow-reply diagnostics, first-event tracing 같은 기능은 운영자가 "왜 느린가", "어디서 막혔는가", "어떤 인증 상태 때문에 제한이 걸렸는가"를 보게 해줍니다. agent 시스템은 실패 원인이 모델, provider, tool, 채널, 세션, 권한 중 어디에 있는지 찾기 어렵습니다. 관측성이 없으면 운영은 추측이 됩니다.
릴리즈 검증도 강화되는 흐름입니다. npm package, registry tarball, integrity hash, GitHub release target, Docker, macOS app validation, E2E, smoke test, plugin publish 검증은 모두 배포 품질의 문제입니다. 설치가 깨지거나, Docker 이미지가 낡은 패키지를 품고 있거나, macOS 앱 검증이 누락되면 현장에서 바로 신뢰를 잃습니다.
쉽게 말하면 이 묶음은 "개발자 장난감이 아니라 운영 가능한 제품처럼 다듬는 작업"입니다. 기능이 많아도 UI가 불안정하거나, 설치가 깨지거나, 릴리즈 품질 검증이 약하면 실제 업무에는 쓰기 어렵습니다.
전체를 한 장으로 보면
최근 변화는 여섯 문장으로 정리할 수 있습니다.
- 채널 계층은 Telegram, WhatsApp, iMessage, Slack 같은 접점에서 에이전트를 안정적으로 부르게 만드는 작업입니다.
- 런타임 계층은 세션, 재시작, transcript, memory, Gateway 복구를 통해 긴 작업을 끝까지 수행하게 만드는 작업입니다.
- 모델/Provider 계층은 OpenAI, Anthropic, Gemini, OpenRouter, Vertex 같은 provider를 갈아끼워도 tool call과 replay가 덜 깨지게 만드는 작업입니다.
- Tool/MCP/Plugin 계층은 검색, 브라우저, 파일, 회의록, 외부 API 같은 실행 능력을 붙이는 작업입니다.
- 보안/권한 계층은 sandbox, exec approval, prompt spoofing, SSRF, 권한 없는 메시지 처리처럼 위험한 실행을 막는 작업입니다.
- UI/운영/릴리즈 계층은 Control UI, WebChat, mobile, diagnostics, Docker, npm, release validation을 통해 사람이 운영할 수 있게 만드는 작업입니다.
OpenClaw를 AI 직원에 비유하면 더 쉽습니다. 채널은 AI 직원에게 연락하는 창구입니다. 런타임은 업무를 끝까지 처리하는 체력과 복구 능력입니다. 모델/Provider는 두뇌 선택지입니다. Tool/MCP/Plugin은 손발입니다. 보안/권한은 출입증과 금지 규칙입니다. UI/운영/릴리즈는 관리자가 배치하고 모니터링하는 운영 화면입니다.
이 비유에서 중요한 건 "두뇌"만으로 AI 직원이 되지 않는다는 점입니다. 실제 업무 환경에서는 연락 창구, 업무 기록, 도구, 권한, 관리 화면이 모두 필요합니다. 최근 OpenClaw 변화는 이 전체 운영체계를 만드는 쪽에 가깝습니다.
운영 관점의 우선순위
제가 본 최근 한 달 변화의 본질은 다음 한 문장입니다.
"여러 메신저에서 에이전트를 부르고, 여러 LLM provider를 붙이고, MCP/plugin으로 외부 도구를 쓰게 하되, 세션 복구와 보안 경계를 강화해서 실제 운영 가능한 구조로 만들고 있다."
운영 관점에서 우선순위를 매기면 저는 보안/권한을 첫 번째로 봅니다. agent는 실제 도구를 실행하기 때문에 위험합니다. 파일, 명령어, 네트워크, 외부 API에 접근하는 순간 보안은 선택이 아니라 기본 조건입니다.
두 번째는 런타임 안정성입니다. 긴 작업이 중간에 끊기면 업무 자동화는 신뢰를 잃습니다. 특히 세션, transcript, memory, replay가 안정적이어야 "어디까지 했고, 어디서 다시 시작할지"를 알 수 있습니다.
세 번째는 채널 안정성입니다. 사용자는 CLI보다 Slack, Telegram, WhatsApp 같은 채널에서 agent를 부를 가능성이 큽니다. 채널이 흔들리면 agent의 품질이 좋아도 사용 경험은 무너집니다.
네 번째는 provider 안정성입니다. 모델을 바꿔도 tool call과 replay가 깨지지 않아야 합니다. 특정 provider에 종속되지 않는 구조는 비용, 품질, 규제, 성능 선택지를 넓혀줍니다.
다섯 번째는 Plugin/MCP 확장성입니다. 실제 업무 자동화의 가치는 외부 도구 연결에서 나옵니다. 다만 확장성은 공급망 보안과 설치 정책을 함께 가져가야 합니다.
여섯 번째는 UI/릴리즈 품질입니다. 운영자가 문제를 보고 고칠 수 있어야 하며, 배포물이 믿을 수 있어야 합니다. 이 영역은 화려하지 않지만 제품 신뢰를 만듭니다.
마무리
OpenClaw의 최근 변화는 "에이전트가 무엇을 답할 수 있는가"보다 "에이전트가 어디서 호출되고, 어떤 모델과 도구를 쓰며, 어떤 권한 안에서, 어떤 기록을 남기고, 실패했을 때 어떻게 복구되는가"에 집중되어 있습니다.
이 방향은 agent 시장 전체의 흐름과도 맞닿아 있습니다. 초기에는 모델 성능과 프롬프트가 중심이었습니다. 그다음에는 tool use와 MCP가 부상했습니다. 이제 운영 단계에서는 세션, 권한, 관측성, 릴리즈 품질이 더 중요해집니다.
결국 agent platform의 경쟁력은 답변 품질 하나로 결정되지 않습니다. 채널, 런타임, provider, tool, 보안, 운영이 하나의 시스템으로 맞물릴 때 실제 업무 환경에 들어갈 수 있습니다.
OpenClaw는 2026년 6월 현재 그 방향으로 빠르게 움직이고 있습니다. 아직 성숙한 엔터프라이즈 플랫폼이라고 단정할 단계는 아니지만, 최근 변화의 초점은 분명합니다. 답변형 AI가 아니라 실행형 AI를 운영하기 위한 하부 구조를 정리하고 있습니다.
이 글은 OpenClaw 공식 저장소와 공개 문서에서 확인할 수 있는 2026년 5월 중순부터 6월 14일까지의 변화 흐름을 바탕으로, Seigniter 관점에서 재구성한 분석입니다.
Next step